func(g *genericScheduler) podFitsOnNode( pluginContext *framework.PluginContext, pod *v1.Pod, meta predicates.PredicateMetadata, info *schedulernodeinfo.NodeInfo, predicateFuncs map[string]predicates.FitPredicate, queue internalqueue.SchedulingQueue, alwaysCheckAllPredicates bool, ) (bool, []predicates.PredicateFailureReason, *framework.Status, error) { var failedPredicates []predicates.PredicateFailureReason var status *framework.Status
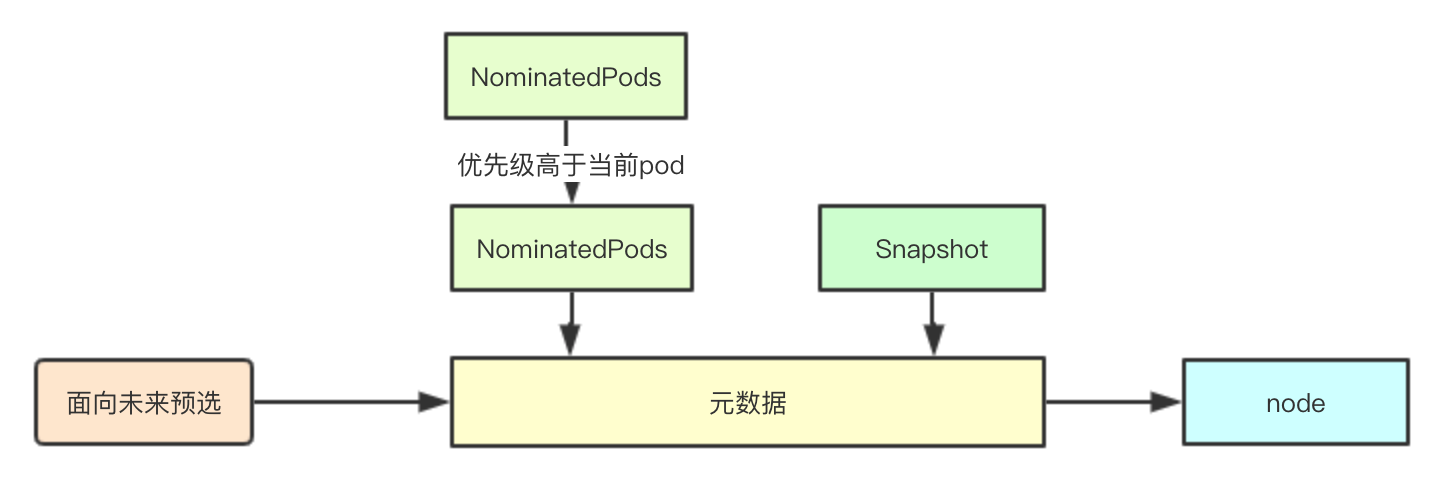
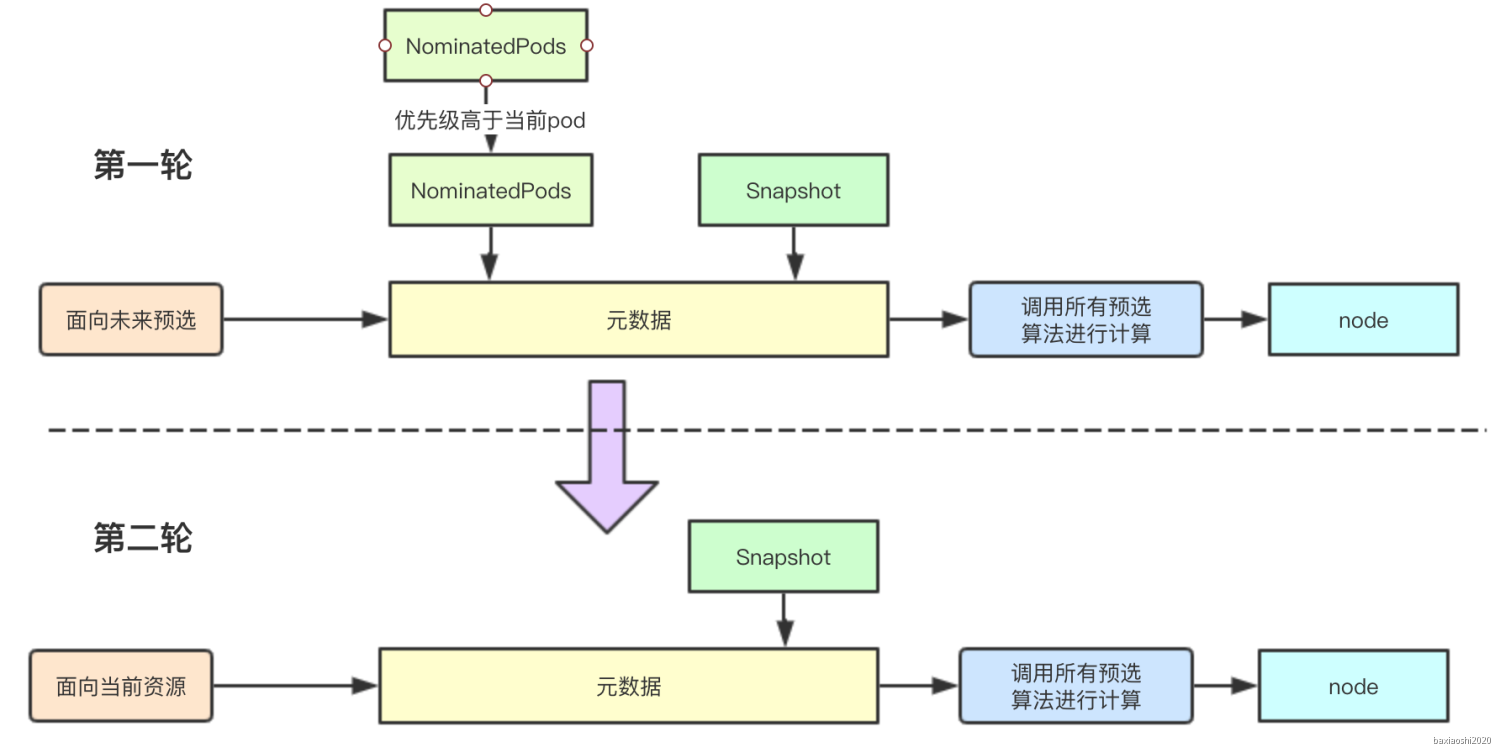
// podsAdded主要用于标识当前是否有提议的pod如果没有提议的pod则就不需要再进行一轮筛选了 podsAdded := false for i := 0; i < 2; i++ { metaToUse := meta nodeInfoToUse := info if i == 0 { // 首先获取那些提议的pod进行第一轮筛选, 如果第一轮筛选出错,则不会进行第二轮筛选 podsAdded, metaToUse, nodeInfoToUse = addNominatedPods(pod, meta, info, queue) } elseif !podsAdded || len(failedPredicates) != 0 { // 如果 break } for _, predicateKey := range predicates.Ordering() { var ( fit bool reasons []predicates.PredicateFailureReason err error ) //TODO (yastij) : compute average predicate restrictiveness to export it as Prometheus metric if predicate, exist := predicateFuncs[predicateKey]; exist { // 预选算法计算 fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse) if err != nil { returnfalse, []predicates.PredicateFailureReason{}, nil, err }
if !fit { // eCache is available and valid, and predicates result is unfit, record the fail reasons failedPredicates = append(failedPredicates, reasons...) // if alwaysCheckAllPredicates is false, short circuit all predicates when one predicate fails. if !alwaysCheckAllPredicates { klog.V(5).Infoln("since alwaysCheckAllPredicates has not been set, the predicate " + "evaluation is short circuited and there are chances " + "of other predicates failing as well.") break } } } }
status = g.framework.RunFilterPlugins(pluginContext, pod, info.Node().Name) if !status.IsSuccess() && !status.IsUnschedulable() { returnfalse, failedPredicates, status, status.AsError() } }