存储基础

存储架构
| 组件 | 功能 |
|---|---|
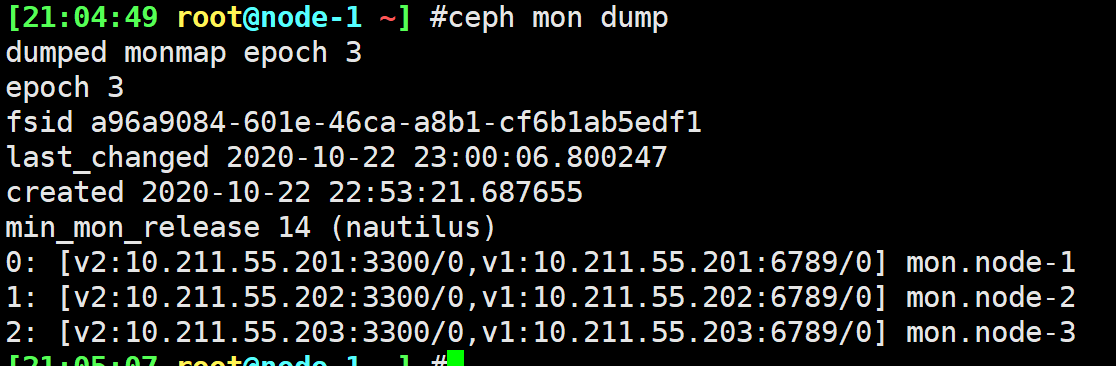
| Monitor | 它是一个在主机上面运行的守护进程,这个守护进程,扮演着监控集群整个组件的职责,包括多少个存储池,存储池中有多少个PG,PG与osd映射的关系,每个节点有多少个osd等等,都要监视,它是整个集群运行图(Cluster Map)的持有者,一共5个运行图。 它还维护集群的认证信息,客户端有用户名密码等;内部的OSD也需要与mon通信,也需要认证,它是通过cephX协议进行认证的,各个组件之间通信,都必须认证,认证都需要经过mon,因此mon还是认证中心,有些同学就会想到,如果集群很大了的话,认证中心会不会成为瓶颈,所以这也是需要多台mon的原因,mon在认证上是无状态的,可以做任意横向扩展,可以使用负载均衡负载的; |
| Managers | 它的专门守护进程是ceph-mgr,负责收集集群的状态指标,运行时的metrics,存储的利用率,当前性能指标和系统负载,它有很多基于Python的插件,以实现ceph-mgr功能的提升,用户辅助mon的。 |
| OSD | Osd是指的单独的资源存储设备,一般情况下一台服务器上面放多块磁盘,ceph为了使用每个节点上面的osd单独进行管理,每一个osd都会有一个单独的、专用的守护进程,比如说,一台服务器上面有6个osd,就需要6个ceph-osd进程,每一个磁盘上面,都有一个守护进程。它提供存储 PG 的数据、数据复制、恢复、再均衡,并提供一些监控信息供mon和mgr来check,并且还可以通过心跳检测其它副本;至少需要有三个osd,不是三台节点哦,这里要注意下,一般情况下我们是1主2从,1主PG、2个副本PG、以确保其高可用性; |
| CURSH | CRUSH 是 Ceph 使用的数据分布算法,类似一致性哈希,让数据分配到预期的位置。 |
| PG | PG 全称 Placement Groups,是一个逻辑的概念,一个 PG 包含多个 OSD 。引入 PG 这一层其实是为了更好的分配数据和定位数据。 |
| Object | 文件需要切分成大小为4M(默认)的块即对象,Ceph 最底层的存储单元就是 Object对象,每个 Object 包含元数据和原始数据; |
| RADOS | 实现数据分配、Failover 等集群操作。 |
| Libradio | librados提供了访问RADOS存储集群支持异步通信的API接口,支持对集群中对象数据的直接并行访问,用户可通过支持的编程语言开发自定义客户端程序通过RADOS协议与存储系统进行交互; |
| MDS | MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务; |
| RBD | RBD全称 RADOS Block Device,是 Ceph 对外提供的块设备服务; |
| RGW | RGW依赖于在RADOS集群基础上独立运行的守护进程(ceph-radosgw)基于http 或https协议提供相关的API服务,不过,通常仅在需要以REST对象形式存取数据时才部署RGW; |
| CephFS | CephFS全称Ceph File System,是 Ceph 对外提供的文件系统服务,它是最早出现的,但也是最后可用于生产的,目前的版本,可以用在生产中。 |
| Admin | Ceph常用管理接口通常都是命令行工具,如rados、ceph、rbd等命令,另外Ceph还有可以有一个专用的管理节点,在此节点上面部署专用的管理工具来实现近乎集群的一些管理工作,如集群部署,集群组件管理等。 |
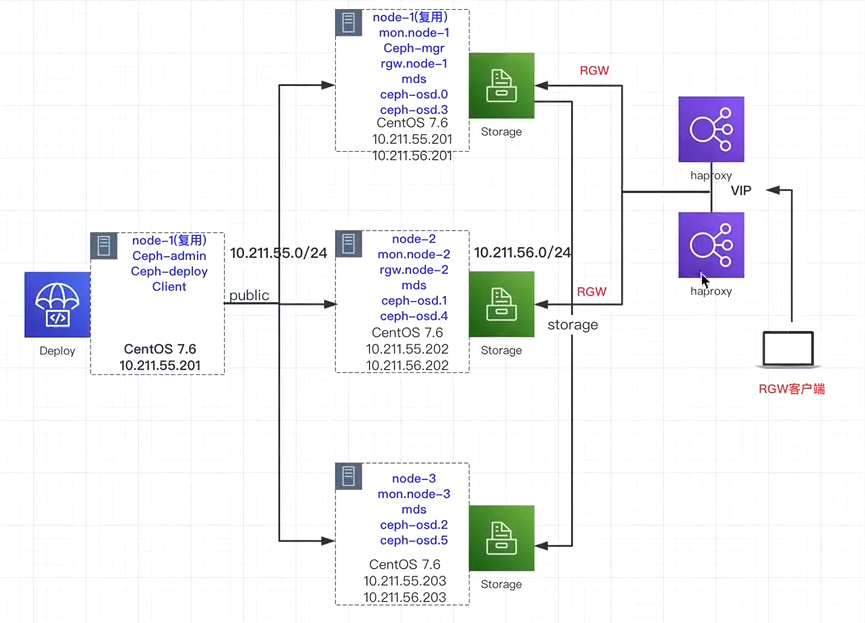
集群部署
主机名和hosts
1 | 10.211.56.201 node-1 |
ssh免密
1 | ssh-keygen |
安全设置
1 | systemctl stop firewalld |
ntp时间同步
yum源
1 | mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup |
安装ceph-deploy
1 | yum install -y python-setuptools |
安装monitor节点
1 | mkdir my-cluster |

1 | yum install -y ceph ceph-mon ceph-mgr ceph-radosgw ceph-mds #所有节点 |
安装osd
先在宿主机挂盘
1 | echo "- - -" > /sys/class/scsi_host/host0/scan |
扩展mon与mgr
1 | ceph-deploy mon add node-2 --address 10.211.55.202 #添加监控节点 |

RBD块存储
介绍

创建资源池Pool
关于存储池
Ceph 存储系统支持“池”概念,它是存储对象的逻辑分区。
Ceph 客户端从监视器获取一张集群运行图,并把对象写入存储池。存储池的 size 或副本数、 CRUSH 规则集和归置组数量决定着 Ceph 如何放置数据。
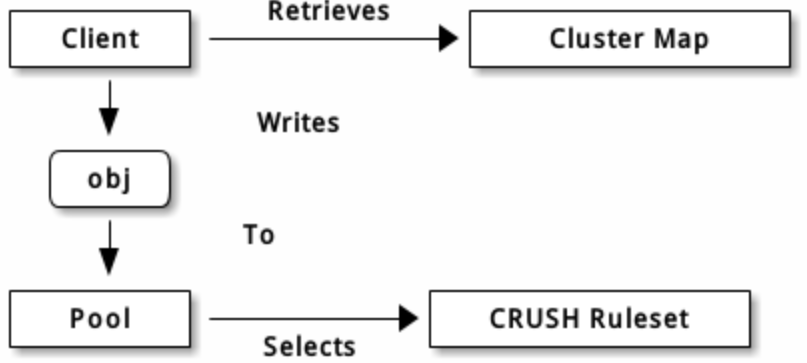
存储池至少可设置以下参数:
- 对象的所有权/访问权限;
- 归置组数量;以及,
- 使用的 CRUSH 规则集。
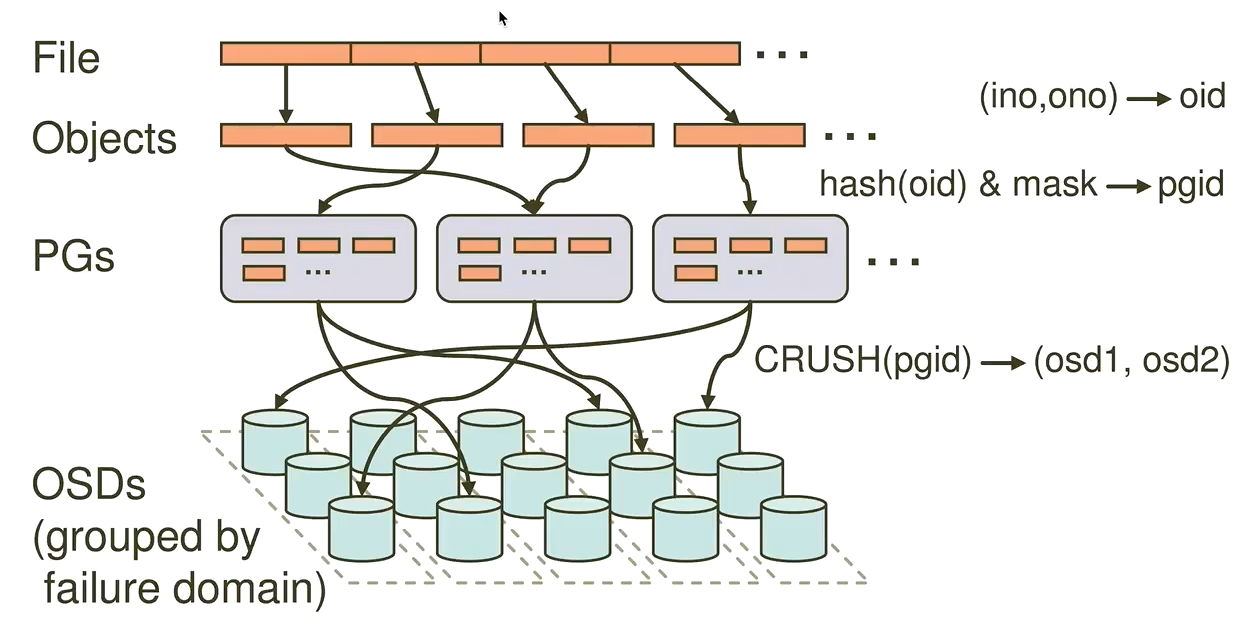
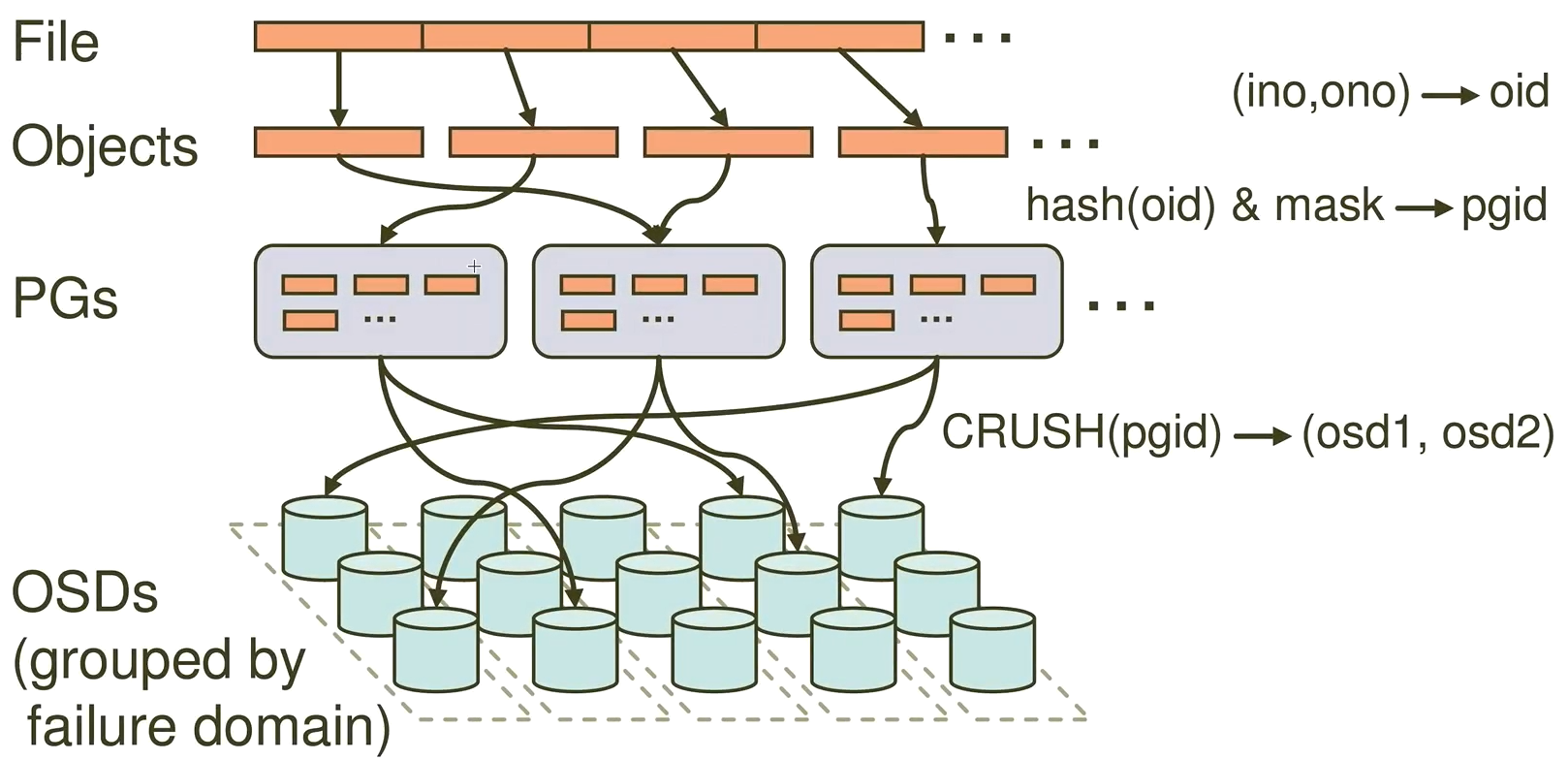
PG 映射到 OSD
每个存储池都有很多归置组, CRUSH 动态的把它们映射到 OSD 。 Ceph 客户端要存对象时, CRUSH 将把各对象映射到某个归置组。
把对象映射到归置组在 OSD 和客户端间创建了一个间接层。由于 Ceph 集群必须能增大或缩小、并动态地重均衡。如果让客户端“知道”哪个 OSD 有哪个对象,就会导致客户端和 OSD 紧耦合;相反, CRUSH 算法把对象映射到归置组、然后再把各归置组映射到一或多个 OSD ,这一间接层可以让 Ceph 在 OSD 守护进程和底层设备上线时动态地重均衡。下列图表描述了 CRUSH 如何将对象映射到归置组、再把归置组映射到 OSD 。
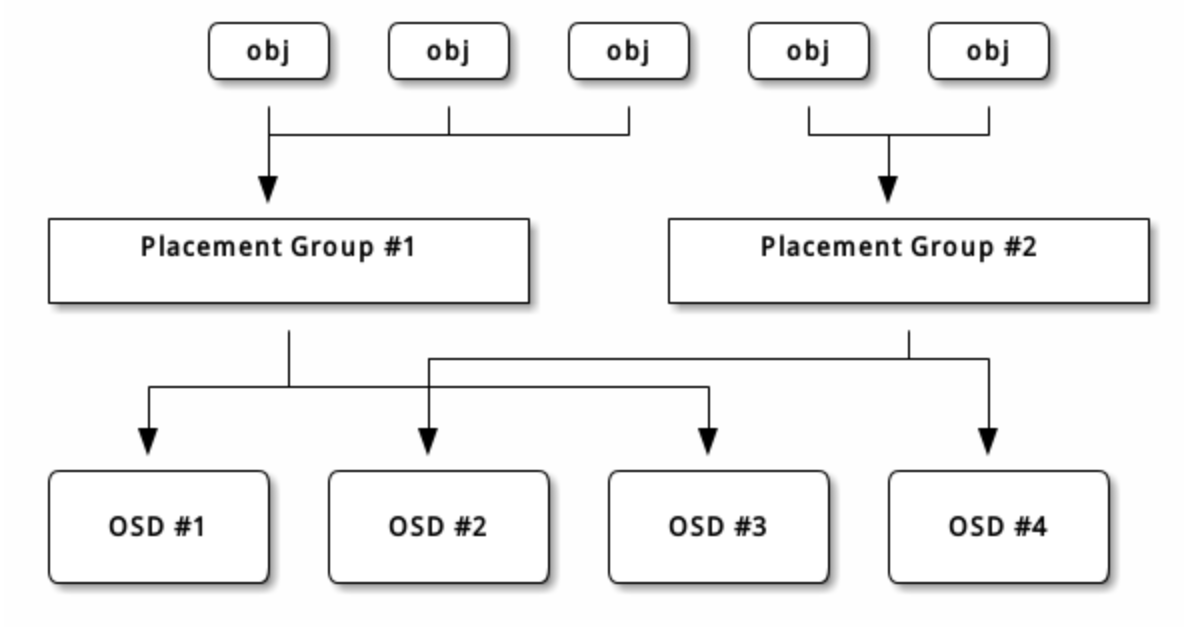
有了集群运行图副本和 CRUSH 算法,客户端就能精确地计算出到哪个 OSD 读、写某特定对象。
1 | ceph osd pool create ceph-demo 32 32 |
RBD创建和映射
1 | rbd create -p ceph-demo --image rbd-demo.img --size 10G |
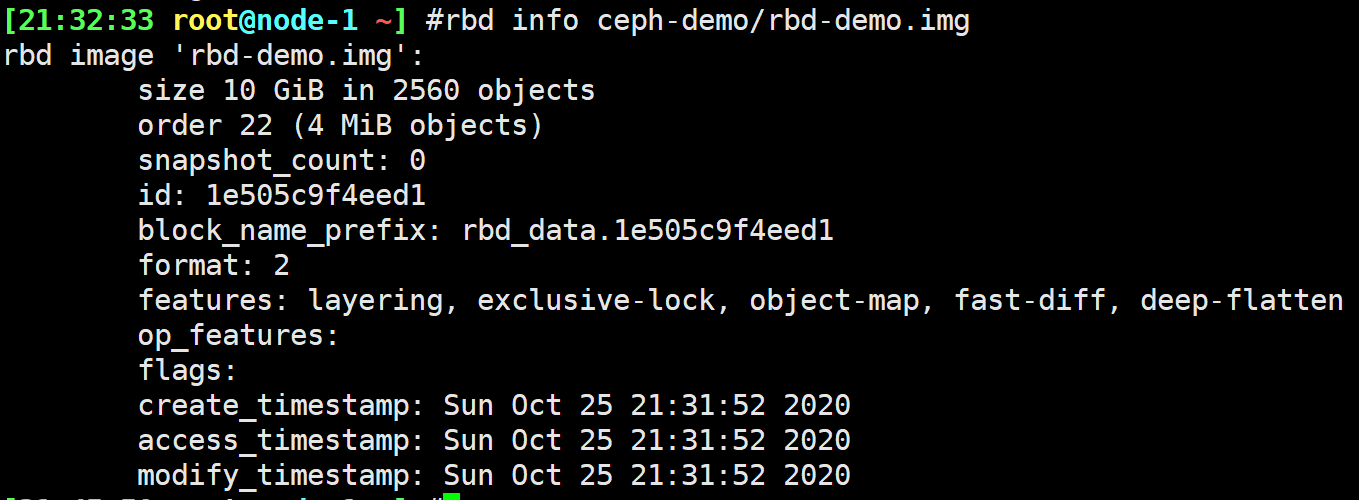
有些参数内核不支持:
升级内核
5+版都支持
去掉参数

1
2
3
4rbd feature disable ceph-demo/rbd-demo.img deep-flatten #从后往前依次关闭特性
rbd feature disable ceph-demo/rbd-demo.img fast-diff
rbd feature disable ceph-demo/rbd-demo.img object-map
rbd feature disable ceph-demo/rbd-demo.img exclusive-lock
映射块设备
1 | rbd map ceph-demo/rbd-demo.img |

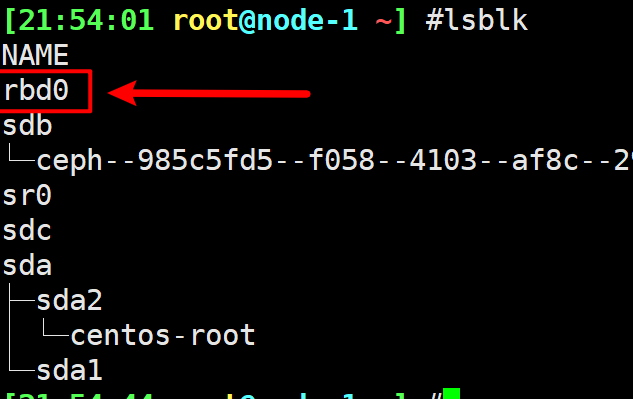
挂载
1 | mkfs.ext4 /dev/rbd0 |
扩容
1 | rbd resize ceph-demo/rbd-demo.img --size 15G #扩容 |
数据流写入过程
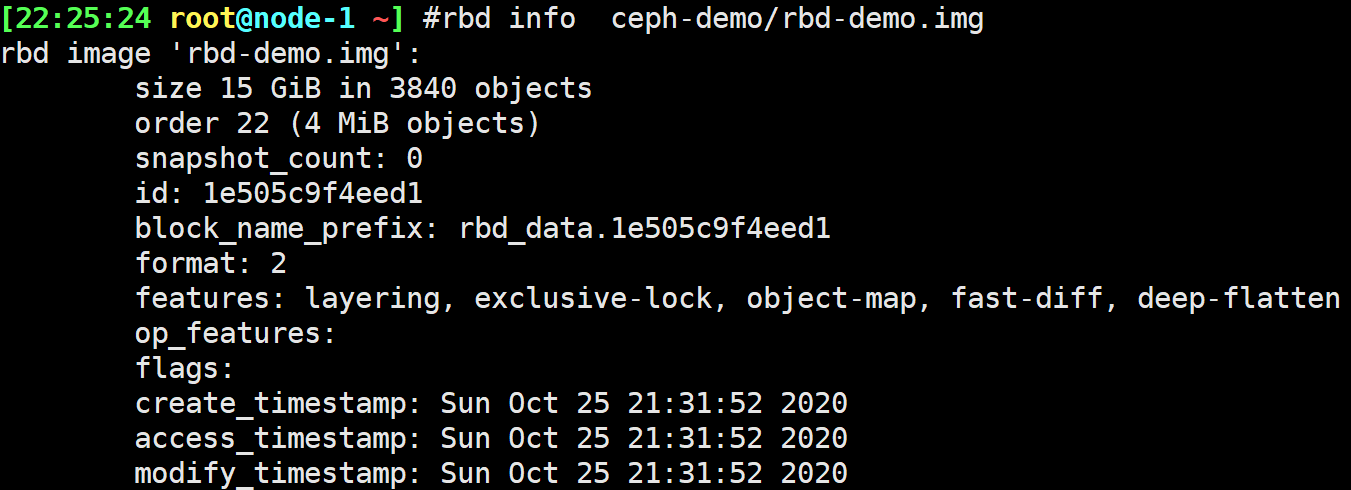
查看对象信息
1 | rbd info ceph-demo/rbd-demo.img #查看pool信息 |

报警排查
1 | ceph -s |
RGW对象存储
简介

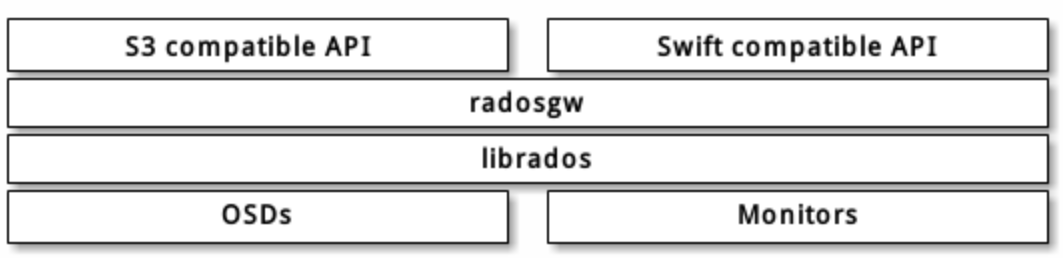
Ceph 对象网关是一个构建在 librados 之上的对象存储接口,它为应用程序访问Ceph 存储集群提供了一个 RESTful 风格的网关 。 Ceph 对象存储支持 2 种接口:
- 兼容S3: 提供了对象存储接口,兼容 亚马逊S3 RESTful 接口的一个大子集。
- 兼容Swift: 提供了对象存储接口,兼容 Openstack Swift 接口的一个大子集。
Ceph 对象存储使用 Ceph 对象网关守护进程( radosgw ),它是个与 Ceph 存储集群交互的 FastCGI 模块。因为它提供了与 OpenStack Swift 和 Amazon S3 兼容的接口, RADOS 要有它自己的用户管理。 Ceph 对象网关可与 Ceph FS 客户端或 Ceph 块设备客户端共用一个存储集群。 S3 和 Swift 接口共用一个通用命名空间,所以你可以用一个接口写如数据、然后用另一个接口取出数据。
1 | [21:49:43 root@node-1 ~] $ rados df |
部署RGW存储网关
1 | #yum list | grep ceph-radosgw |
修改RGW默认端口
1 | #修改ceph配置文件 |
S3接口使用
1 | $ radosgw-admin user create --uid="ceph-s3-user" --display-name="Ceph S3 User Demo" #创建用户 |
测试 S3 访问
为了验证 S3 访问,你需要编写并运行一个 Python 测试脚本。S3 访问测试脚本将连接 radosgw, 新建一个新的 bucket 并列出所有的 buckets。 aws_access_key_id 和 aws_secret_access_key 的值来自于命令radosgw_admin 的返回值 access_key 和 secret_key 。
执行下面的步骤:
你需要安装
python-boto包:1
sudo yum install python-boto
新建 Python 脚本文件:
1
vi s3test.py
将下面的内容添加到文件中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import boto
import boto.s3.connection
access_key = 'LGHYIQC44CM0T7BHKW2U'
secret_key = 'olbc2icqlZwT3JA9d3dx86JAOIGtLZbopdneH8gu'
conn = boto.connect_s3(
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
host='10.211.55.201', port=7480,
is_secure=False, # uncomment if you are not using ssl
calling_format=boto.s3.connection.OrdinaryCallingFormat(),
)
bucket = conn.create_bucket('my-new-bucket')
for bucket in conn.get_all_buckets():
print
"{name} {created}".format(
name=bucket.name,
created=bucket.creation_date,
)将
{hostname}替换为你配置了网关服务的节点的主机名。比如gateway host. 将 {port} 替换为 Civetweb 所使用的端口。运行脚本:
1
python s3test.py
输出类似下面的内容:
1
my-new-bucket 2015-02-16T17:09:10.000Z #个人做实验不会输出,但bucket已创建
S3cmd使用
配置文件
1 | # yum install s3cmd |
创建Bucket
1 | $ s3cmd mb s3://test-demo |
坑:
1 | [22:06:38 root@node-1 ~/my-cluster] #s3cmd put /etc/fstab s3://my-new-bucket/fstab-demo |
文件操作
1 | $ s3cmd put /etc/fstab s3://test-demo/fstab-demo |


1 | $ ceph osd lspools |
swift风格api接口
- 需要新建一个 Swift 子用户
- 创建 Swift 用户包括两个步骤。第一步是创建用户。第二步是创建 secret key。
新建 Swift 用户:
1 | radosgw-admin subuser create --uid=ceph-s3-user <--主用户id> --subuser=ceph-s3-user:swift --access=full |
新建 secret key:
1 | radosgw-admin key create --subuser=ceph-s3-user:swift --key-type=swift --gen-secret |
1 | "secret_key": "bVLptVg3gFoyXzEFY2Trg4uMAXHP5954hkdl0vTr" |
测试
1 | #安装环境 |
文件操作
1 | $ swift post swift-demo |
查找文件
所有资源都是以对象的形式存储在资源池pool中,对象最终会映射到pg上,再由pg落盘到osd上
1 | #rados -p default.rgw.buckets.data ls |
CephFs文件系统

1 | #挂载安装依赖 |
组件架构
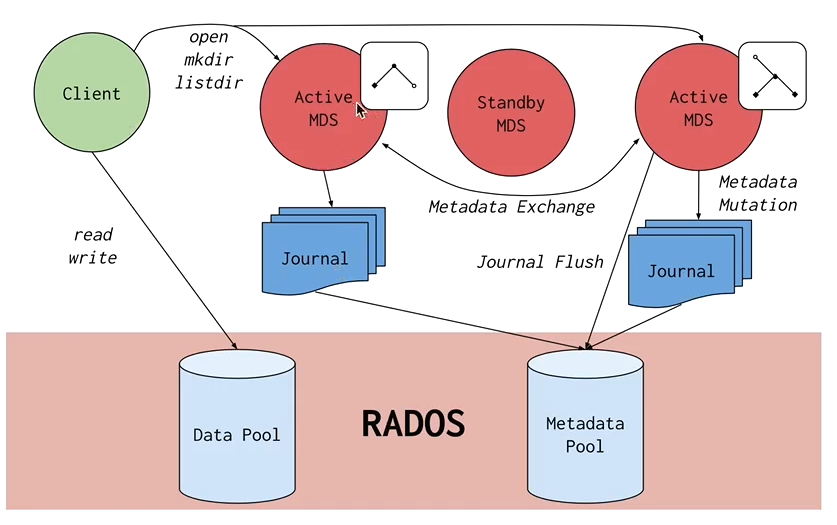
Ceph文件系统或CephFS是在Ceph的分布式对象存储RADOS之上构建的POSIX兼容文件系统。CephFS致力于为各种应用程序提供最新,多用途,高可用性和高性能的文件存储,包括传统用例(如共享主目录,HPC暂存空间和分布式工作流共享存储)。
CephFS通过使用一些新颖的架构选择来实现这些目标。值得注意的是,文件元数据与文件数据存储在单独的RADOS池中,并通过可调整大小的元数据服务器或MDS集群提供服务,该集群可扩展以支持更高吞吐量的元数据工作负载。文件系统的客户端可以直接访问RADOS来读写文件数据块。因此,工作负载可能会随着基础RADOS对象存储的大小线性扩展。也就是说,没有网关或代理为客户端中介数据I / O。
通过MDS集群协调对数据的访问,该集群充当客户端和MDS共同维护的分布式元数据缓存状态的授权机构。每个MDS都会将对元数据的突变汇总为对RADOS上日记的一系列有效写入。MDS不会在本地存储任何元数据状态。此模型允许在POSIX文件系统的上下文中客户端之间进行连贯且快速的协作。
安装部署MDS集群
1 | $ cd ceph-deploy/ |
创建文件系统
1 | $ ceph osd pool create cephfs_data 16 16 |
内核挂载
{path-to-be-mounted}是CephFS中将要挂载的路径, {mount-point}是文件系统中将要挂载CephFS的点,并且{user-name}是有权在机器上挂载CephFS的CephX用户的名称。以下命令是扩展形式,但是这些额外的细节由mount.ceph帮助程序自动找出:
1 | $ mount -t ceph {ip-address-of-MON}:{port-number-of-MON}:{path-to-be-mounted} -o name={user-name},secret={secret-key} {mount-point} |
如果群集上有多个文件系统,则需要将fs={fs-name}option传递 给-ooption mount:
1 | sudo mount -t ceph :/ /mnt/kcephfs2 -o name=admin,fs=mycephfs2 |
1 | lsmod | grep ceph |
用户态挂载
要使用FUSE(用户空间中的文件系统)挂载CephFS,请运行:
1 | yum install ceph-fuse -y |
要在CephFS中挂载特定目录,您可以使用-r:
1 | ceph-fuse -r {path-to-be-mounted} /mnt/mycephfs |
如果群集上有多个文件系统,则需要传递 给命令:--client_fs {fs-name}``ceph-fuse
1 | ceph-fuse /mnt/mycephfs2 --client_fs mycephfs2 |
osd扩容与换盘
osd纵向扩容
1 | $ ceph-deploy disk list node-1 #查看节点磁盘 |
数据rebalancing重分布
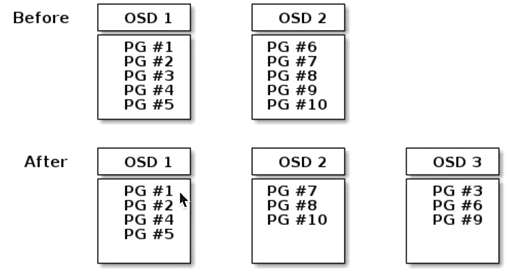
当您将Ceph OSD守护程序添加到Ceph存储群集时,群集映射将使用新的OSD更新。再次参考计算PG ID,这将更改群集映射。因此,它更改了对象放置,因为它更改了计算的输入。下图描述了重新平衡过程(尽管相当粗略,因为它对大型集群的影响较小),其中一些(但不是全部)PG从现有OSD(OSD 1和OSD 2)迁移到新OSD(OSD 3) )。即使重新平衡,破碎也很稳定。许多放置组仍保持其原始配置,并且每个OSD都增加了一些容量,因此重新平衡完成后,新OSD上不会出现负载峰值。
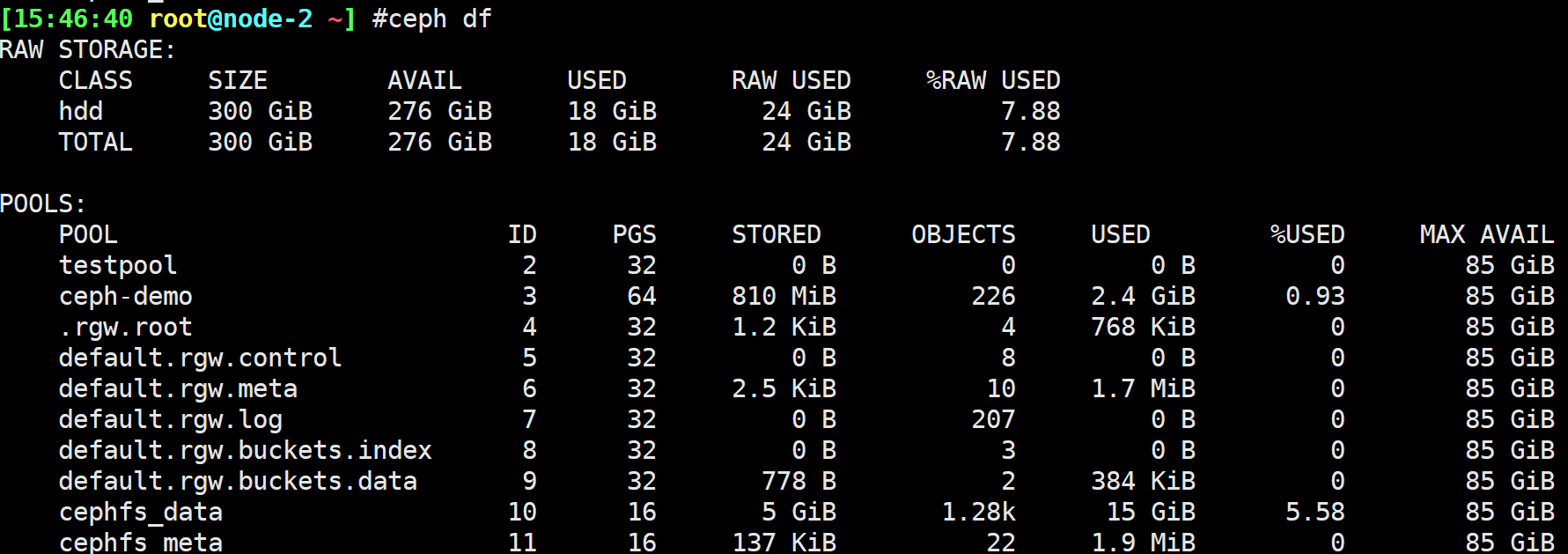
1 | $ ceph df |
1 | dd if=/dev/zero of=rebalancing-file.img bs=1M count=5120 |
1 | cp rebalancing-file.img /mnt/rbd-demo/ |
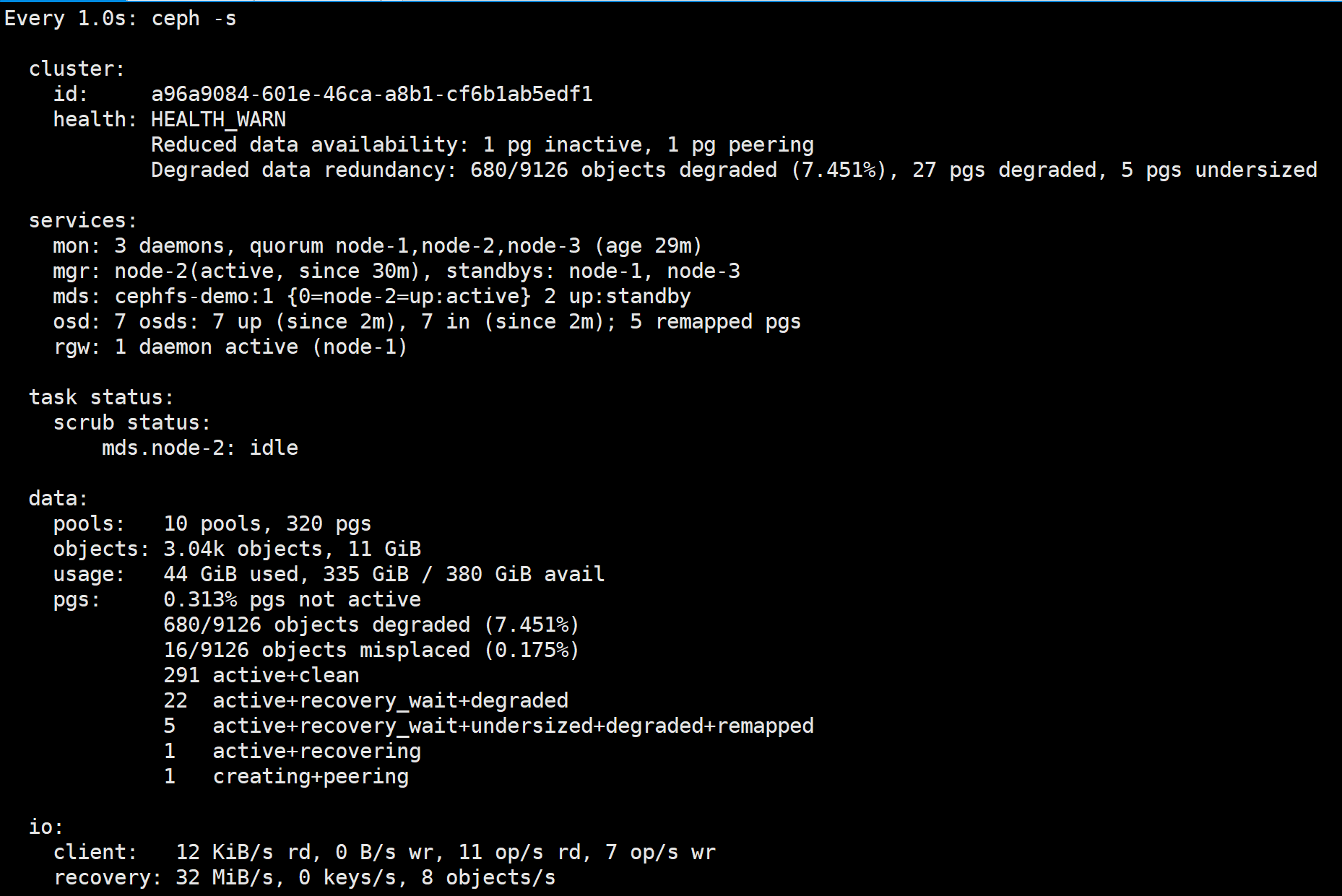
recovery流量进行数据重分布
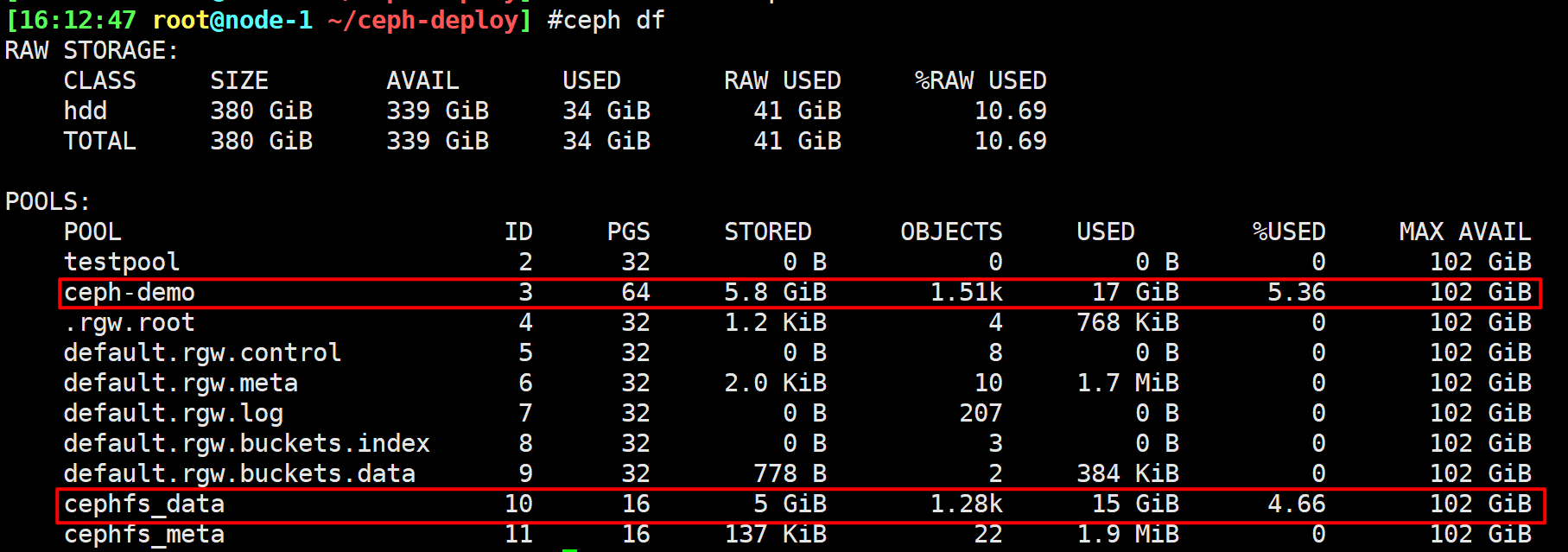
临时关闭rebalancing
1 | ceph --admin-daemon /var/run/ceph/ceph-mon.node-1.asok config show| grep max_backfills |
1 | $ ceph osd set norebalance #关闭数据分布标志位 |
osd坏盘更换
1 | dmesg #查看日志信息 |
删除OSD,通常为up和in。您需要将其从群集中删除,以便Ceph可以开始重新平衡并将其数据复制到其他OSD。
1 | ceph osd out {osd-num} |
模拟坏盘
1 | $ ceph osd tree |
- 坏盘后大约10分钟后数据重分布
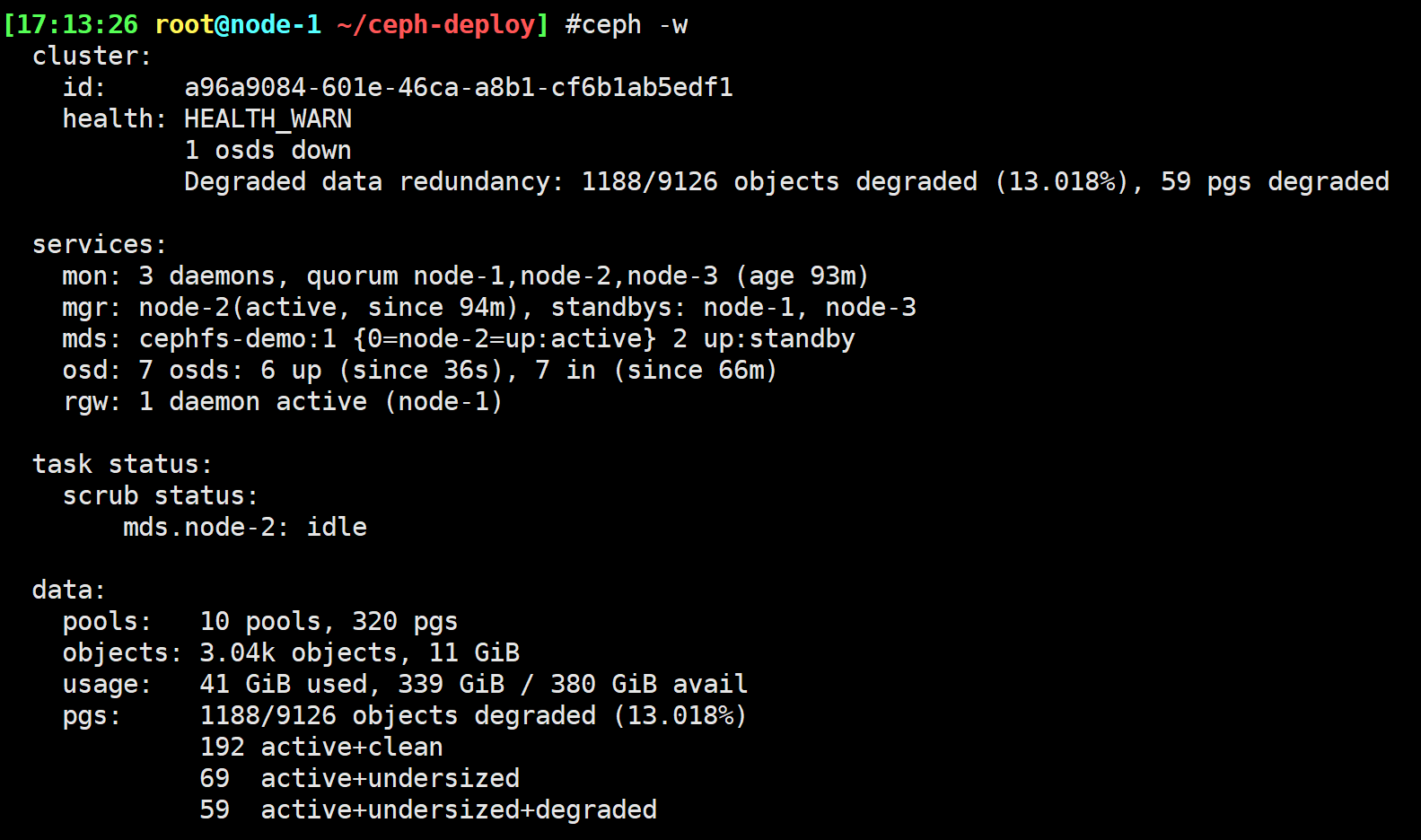
1 | $ ceph osd out osd.6 |
步骤:
- ceph osd out 驱逐
- ceph osd crush rm osd.6删除osd.6 crush算法
- ceph osd rm osd.6 #删除osd
- ceph auth rm osd.6 #删除认证
数据一致性检查DATA CONSISTENCY
作为保持数据一致性和整洁度的一部分,Ceph OSD还可以清理放置组中的对象。也就是说,Ceph OSD可以将一个放置组中的对象元数据与其存储在其他OSD中的放置组中的副本进行比较。
清理(通常每天执行一次)会捕获OSD错误或文件系统错误。OSD还可以通过逐位比较对象中的数据来执行更深入的清理。
深度清理(通常每周执行一次)会发现磁盘上的坏扇区在轻度清理中并不明显。
Ceph清理类似于fsck对象存储层上的清理。对于每个pg,Ceph都会生成所有对象的目录,并比较每个主要对象及其副本,以确保没有对象丢失或不匹配。轻擦洗(每天)检查对象的大小和属性。深度清理(每周一次)读取数据并使用校验和以确保数据完整性。
清理有两种,针对pg,针对osd
1 | $ ceph pg dump #获取pg_id |
出现deep scrub
ceph集群运维
守护服务管理
1 | systemctl start ceph.target # 对应所有服务 |
要列出节点上的Ceph systemd单元
1 | systemctl status ceph\*.service ceph\*.target | grep Load |
按类型
1 | systemctl start ceph-osd.target #对应所有osd的守护进程 |
特定的守护程序实例
1 | systemctl start ceph-osd@1 |
服务日志分析
/var/log/ceph(默认位置)下查看Ceph日志文件
集群状态监控
集群
要ceph以交互方式运行该工具,请ceph在命令行中键入,不带参数。例如:
1 | ceph |
ceph -s = ceph status
1 | ceph -s = ceph status |
存储
要检查集群在池中的数据使用情况和数据分布,可以使用该df选项。它类似于Linux df。执行以下命令:
1 | ceph df |
输出的RAW STORAGE部分提供了群集管理的存储量的概述。
类别: OSD设备的类别(或群集的总数)
大小:集群管理的存储容量。
可用:自由空间的集群中使用的量。
已用:用户数据消耗的原始存储量。
原始使用量:用户数据,内部开销或保留的容量消耗的原始存储量。
已用%RAW:已用原始存储空间的百分比。将此数字与和结合使用,以确保未达到群集的容量。有关更多详细信息,请参见存储容量。
full ratio near full ratio
输出的POOLS部分提供了池的列表以及每个池的概念用法。本节的输出不反映副本,克隆或快照。例如,如果存储的对象具有1MB的数据,则名义使用量将为1MB,但实际使用量可能为2MB或更多,具体取决于副本,克隆和快照的数量。
- NAME:池的名称。
- ID:池ID。
- 已使用:名义上存储的数据量(以千字节为单位),除非数字在M(兆字节)后附加G(千兆字节)。
- %USED:每个池使用的名义存储百分比。
- MAX AVAIL:可以写入此池的名义数据量的估计值。
- 对象:每个池中存储的对象的名义数量。
注意:
POOLS部分中的数字是名义上的。它们不包括副本,快照或克隆的数量。其结果是,在总和USED和%USED金额不会加起来 USED和%USED的数量RAW输出的部分。
该MAX AVAIL值是用于复制或纠删码的复杂函数,映射到存储设备上的CRUSH规则,这些设备的利用率,以及配置的mon_osd_full_ratio。
osd
1 | ceph osd status |
mon
1 | ceph mon stat |
要检查监视器群集的仲裁状态,请执行以下操作:
1 | ceph quorum_status | jq |
mds
1 | ceph mds stat |
使用socket
1 | ceph --admin-daemon /var/run/ceph/ceph-mon.node-1.asok help | jq |
POOL管理
首次部署群集而不创建池时,Ceph使用默认池来存储数据。
- 弹性Resilience:可以设置允许多少OSD发生故障而不丢失数据。对于复制池,它是对象的所需副本数/副本数。典型的配置存储一个对象和一个附加副本,但是您可以确定副本/副本的数量。对于擦除编码池,它是编码块的数量(即在擦除代码配置文件中**)
size = 2``m=2 - Placement Groups:您可以设置池的放置组数。一个典型的配置每个OSD使用大约100个放置组,以提供最佳的平衡,而不会消耗太多的计算资源。设置多个池时,请确保为池和整个群集设置合理数量的放置组。
- CRUSH规则:将数据存储在池中时,对象及其副本(或用于擦除编码池的块)在群集中的位置由CRUSH规则控制。如果默认规则不适用于您的用例,则可以为您的池创建自定义的CRUSH规则。
- 快照:使用创建快照时,可以有效地为特定池拍摄快照。
ceph osd pool mksnap
1 | ceph osd lspools |

将pool关联到应用程序
对于其他情况,您可以手动将自由格式的应用程序名称关联到池。
1 | ceph osd pool application enable {pool-name} {application-name} |
- CephFS使用应用程序名称
cephfs,RBD使用应用程序名称rbd,而RGW使用应用程序名称rgw。
1 | $ ceph osd pool application get testpool |
设置pool配额
您可以将池配额设置为每个池的最大字节数和/或最大对象数。
1 | ceph osd pool set-quota {pool-name} [max_objects {obj-count}] [max_bytes {bytes}] |
例如:
1 | $ ceph osd pool set-quota testpool max_objects 100 |
删除配额,将其值设置为0。
重命名
要重命名池,请执行:
1 | ceph osd pool rename {current-pool-name} {new-pool-name} |
如果重命名池,并且您具有针对经过身份验证的用户的每个池功能,则必须使用新的池名称更新用户的功能(即上限)。
pool利用率
1 | rados df |
要获取特定池或全部池的I / O信息,请执行以下操作:
1 | ceph osd pool stats |
命名一个pool
1 | ceph osd pool rename {current-pool-name} {new-pool-name} |
如果重命名了一个存储池,且认证用户有每存储池能力,那你必须用新存储池名字更新用户的能力(即 caps )。
pool参数
https://docs.ceph.com/en/octopus/rados/operations/pools/#set-pool-values
pg数据分布
存储池内的归置组( PG )把对象汇聚在一起,因为跟踪每一个对象的位置及其元数据需要大量计算——即一个拥有数百万对象的系统,不可能在对象这一级追踪位置。
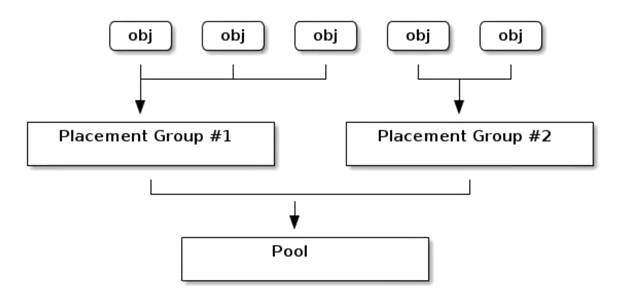
Ceph 客户端会计算某一对象应该位于哪个归置组里,它是这样实现的,先给对象 ID 做哈希操作,然后再根据指定存储池里的 PG 数量、存储池 ID 做一个运算。
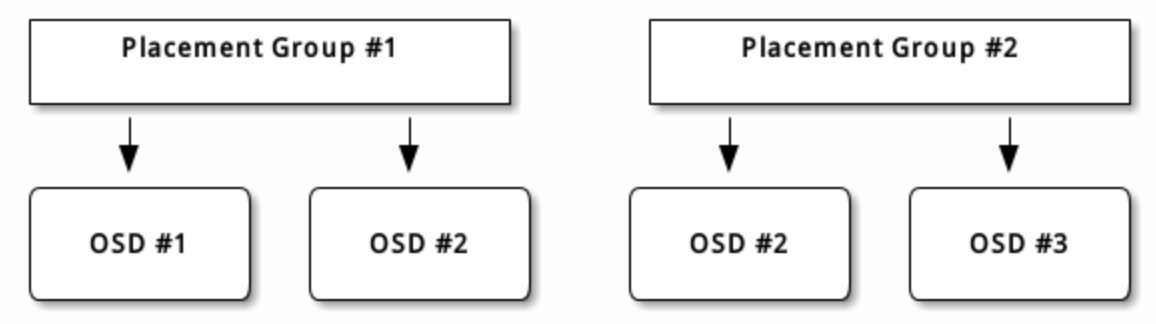
计算pg

总pg数 = (OSD数量 * 100) / pool 副本数(默认为3)
然后取其最近的 2的n次方
1 | (200*100)/3=6667 #去最近2的n次方: 4096或8192 |
创建pool是指定大小
1 | $ ceph osd pool set mypool target_size_bytes 100T |
如果mypool是群集中唯一的池,则意味着预期使用了总容量的100%。
如果第二个池的target_size_ratio= 1.0,则两个池都将使用50%的群集容量。
如果指定了不可能的目标大小值(例如,容量大于整个群集的容量),则会发出健康警告(POOL_TARGET_SIZE_BYTES_OVERCOMMITTED)。
如果为池指定了target_size_ratio和target_size_bytes,则仅考虑比率,并发出运行状况警告(POOL_HAS_TARGET_SIZE_BYTES_AND_RATIO)。
指定池的PG的边界
也可以为一个池指定最小数量的PG。这对于确定执行IO时客户端将看到的并行度的数量的下限很有用,即使池中大多数都是空的。设置下限可以防止Ceph将PG编号减少(或建议减少)到配置的编号以下。
您可以使用以下方法设置池的最小PG数量:
1 | ceph osd pool set <pool-name> pg_num_min <num> |
您也可以使用命令的可选参数来指定创建池时的最小PG数量。
1 | ceph osd pool create --pg-num-min <num> |
CEPH参数调整配置
删除pool
要删除一存储池,执行:
1 | ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it] |
如果你给自建的存储池创建了定制的规则集,你不需要存储池时最好删除它。如果你曾严格地创建了用户及其权限给一个存储池,但存储池已不存在,最好也删除那些用户。
调整CRUSH MAP
简介
CRUSH 算法通过计算数据存储位置来确定如何存储和检索。 CRUSH 授权 Ceph 客户端直接连接 OSD ,而非通过一个中央服务器或代理。数据存储、检索算法的使用,使 Ceph 避免了单点故障、性能瓶颈、和伸缩的物理限制。
CRUSH 需要一张集群的 Map,且使用 CRUSH Map 把数据伪随机地、尽量平均地分布到整个集群的 OSD 里。CRUSH Map 包含 OSD 列表、把设备汇聚为物理位置的“桶”列表、和指示 CRUSH 如何复制存储池里的数据的规则列表。
bucket是层次结构中内部节点(主机,机架,行等)的CRUSH术语。CRUSH映射定义了一系列用于描述这些节点的类型。默认情况下,这些类型包括:
- osd(或设备)
- 主机host
- 机壳
- 机架
- 行
- pdu
- pod
- 机房
- 数据中心
- 区
- 地区
- 根
大多数群集仅使用其中少数几个类型,可以根据需要定义其他类型。
该层次结构是通过osd在叶子的设备(通常为type ),内部节点(具有非设备类型)和type的根节点 构建的root。例如,
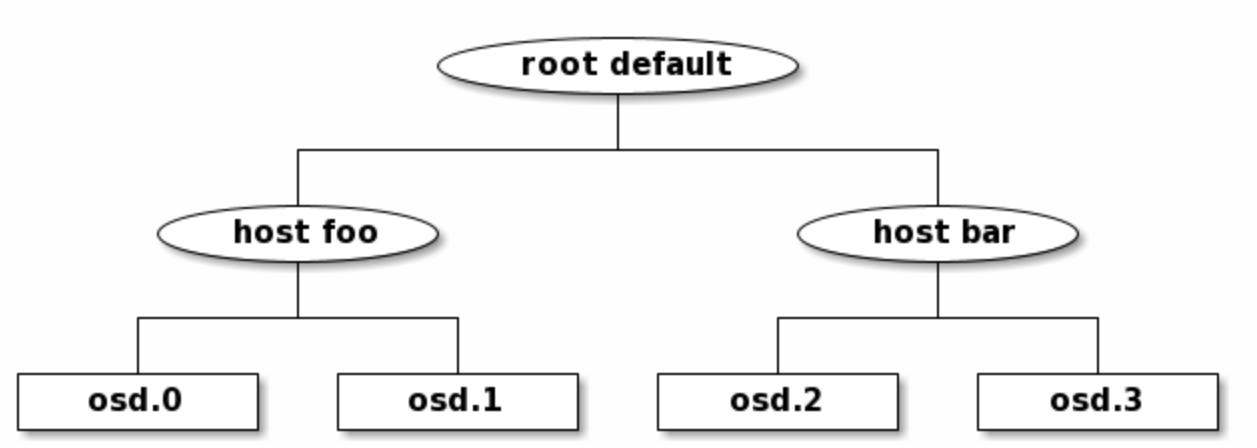
规则剖析
查看规则树:
1 | $ ceph osd crush tree |
1 | { |
定制CRUSH拓扑架构
CRUSH Map 主要有 4 个段落。
- 设备:由任意对象存储设备组成,即对应一个 ceph-osd进程的存储器。 Ceph 配置文件里的每个 OSD 都应该有一个设备。
- 桶类型: 定义了 CRUSH 分级结构里要用的桶类型( types ),桶由逐级汇聚的存储位置(如行、机柜、机箱、主机等等)及其权重组成。
- 桶实例: 定义了桶类型后,还必须声明主机的桶类型、以及规划的其它故障域。
- 规则: 由选择桶的方法组成。
要编辑现有的CRUSH映射,请执行以下操作:
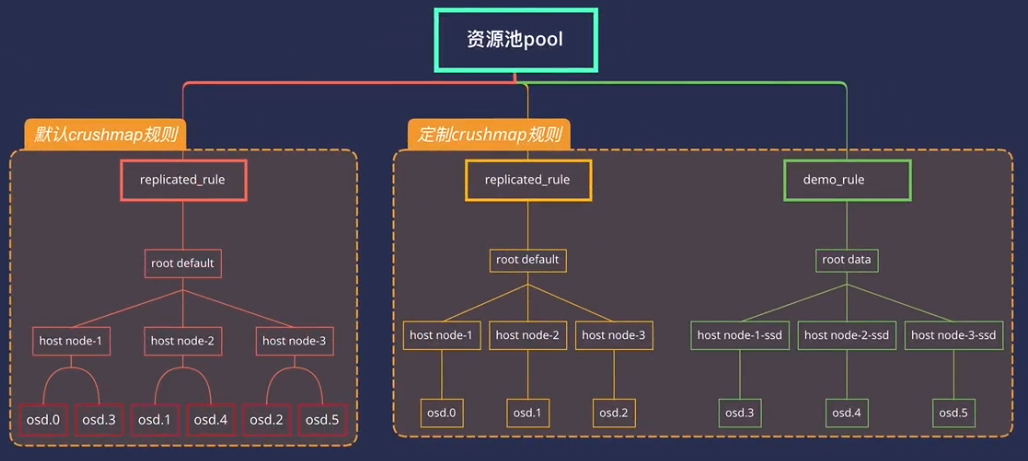
两种修改方式
手动编辑
1 | $ ceph osd getcrushmap -o crushmap.bin #保存crushmap二进制文件 |
1 | # begin crush map |
1 | $ crushtool -c crushmap.txt -o crushmap-new.bin #编译新规则文件 |
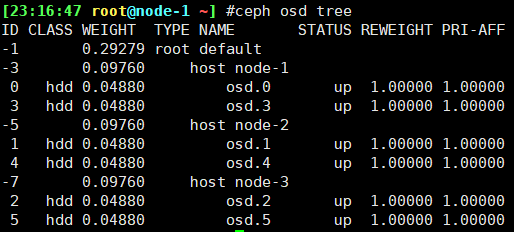
应用规则
1 | $ ceph osd setcrushmap -i crushmap-new.bin |
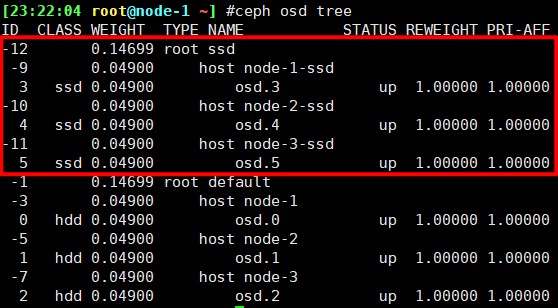
修改rule
1 | $ ceph osd lspools |
命令行调整
已将crush恢复初始
1 | $ ceph osd crush add-bucket ssd root #从上往下,先添加顶层bucket |
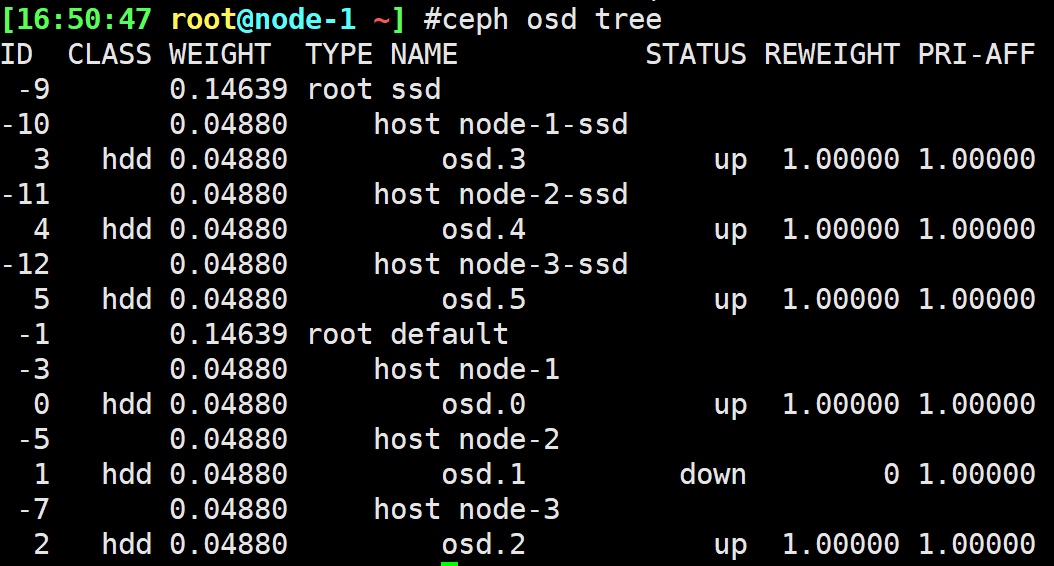
1 | # 修改osd class |
注意事项
操作前先备份
保留每次修改的bin文件
初始就规划好
重启osd crushmap会变动
1
2
3
4
5
6#增加osd配置文件
[osd]
osd crush update on start = flase
ceph-deploy --overwrite-conf config push node-1 node-2 node-3
# 重启osd
systemctl reset-failed ceph-osd@0.service增加配置后新加osd需手动添加crushmap
RBD高级功能
RBD回收站机制
正常的 rbd image 一旦删除了就没了,但是 ceph rbd 提供了回收站方式给你反悔的机会。
实验
1 | $ rbd create ceph-demo/ceph-trash.img --size 1G |
镜像制作快照
1 | $ rbd create ceph-demo/rbd-tst.img --image-feature layering --size 1G |
快照数据恢复
1 | $ rm /media/file1 -f |
删除RBD
1 | #全部卸载 |
镜像克隆机制
Ceph支持创建块设备快照的许多写时复制(COW)克隆的功能。快照分层使Ceph块设备客户端可以非常快速地创建图像。例如,您可能会在写入了Linux VM的情况下创建块设备映像。然后,对映像进行快照,保护快照,并根据需要创建尽可能多的写时复制克隆。快照是只读的,因此克隆快照可以简化语义,从而可以快速创建克隆。
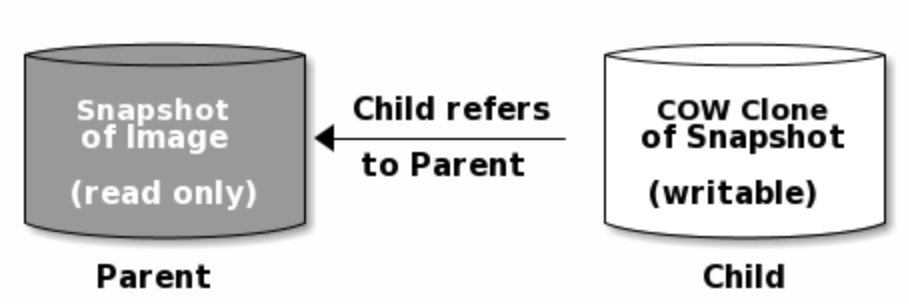
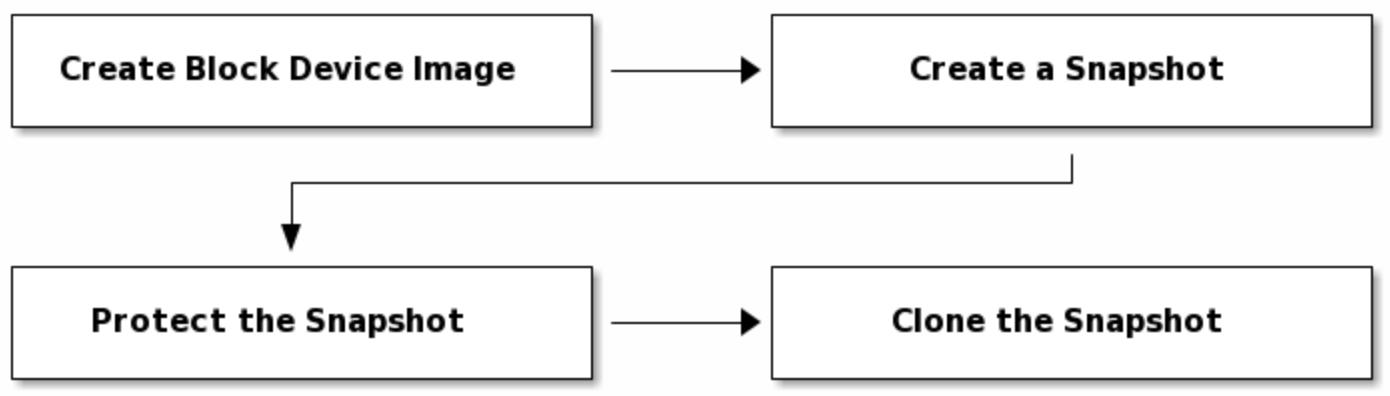
1 | # rbd clone {pool-name}/{parent-image}@{snap-name} {pool-name}/{child-image-name} |
快照子项
1 | ##rbd children {pool-name}/{image-name}@{snapshot-name} |
解除依赖关系
1 | #rbd flatten {pool-name}/{image-name} |
RBD备份与恢复
1 | $ rbd export ceph-demo/vm2-clone.img /root/test.img #备份 |
增量备份与恢复
1 | $ echo 111 > /media/file20201111-new |
导入导出总结
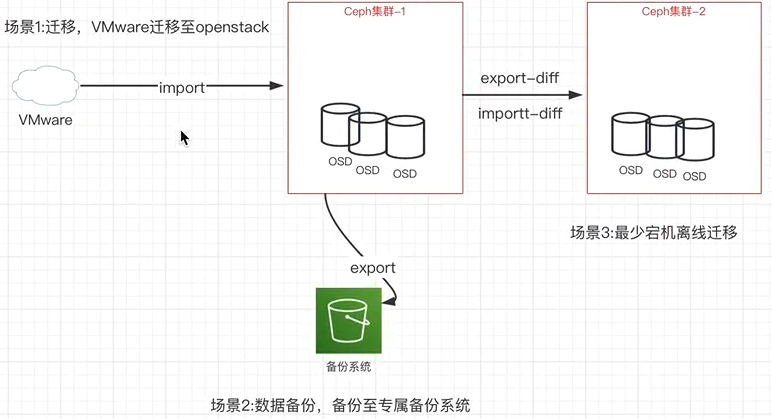
RGW高可用集群
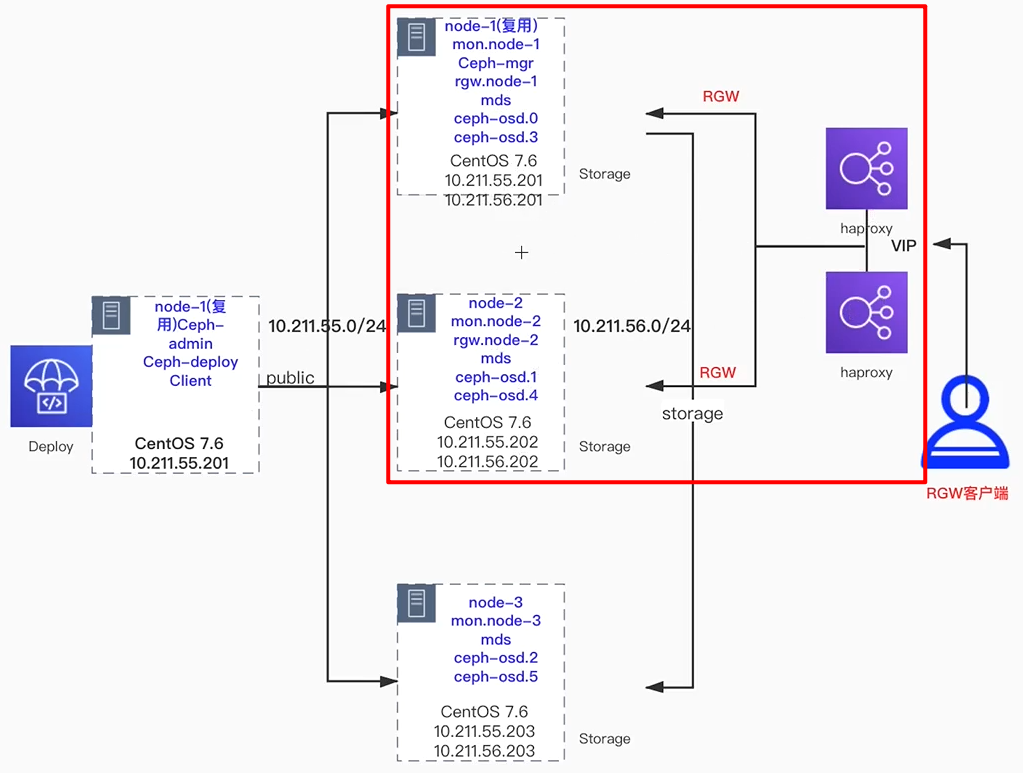
拓展RGW集群
之前部署只有一个RGW网关
1 | $ cd ceph-deploy |
可以修改端口

搭建高可用环境
| 主机名 | IP地址 | 端口 | 软件 | VIP+端口 |
|---|---|---|---|---|
| node-1 | 10.211.55.201 | 81 | rgw+ha+kp | 10.211.55.200:80 |
| node-2 | 10.211.55.202 | 81 | rgw+ha+kp | 10.211.55.200:8 |
配置keepalived
1 | $ yum install keepalived libnl3-devel ipset-devel -y |
1 | #### node-2 |
配置haproxy
1 | global |
修改客户端指向
s3
1 | $ vim ~/.s3cfg |
swift
1 | #修改环境变量/etc/profile |
CEPH集群测试
mon
模式为选举 最多挂n/2-1
1 | #配置文件 |
mds
模式为一主多备,确保集群中至少有1个
RGW
ha+kp高可用
OSD坏盘
对象为3副本,最多挂2个节点
fio性能压测评估
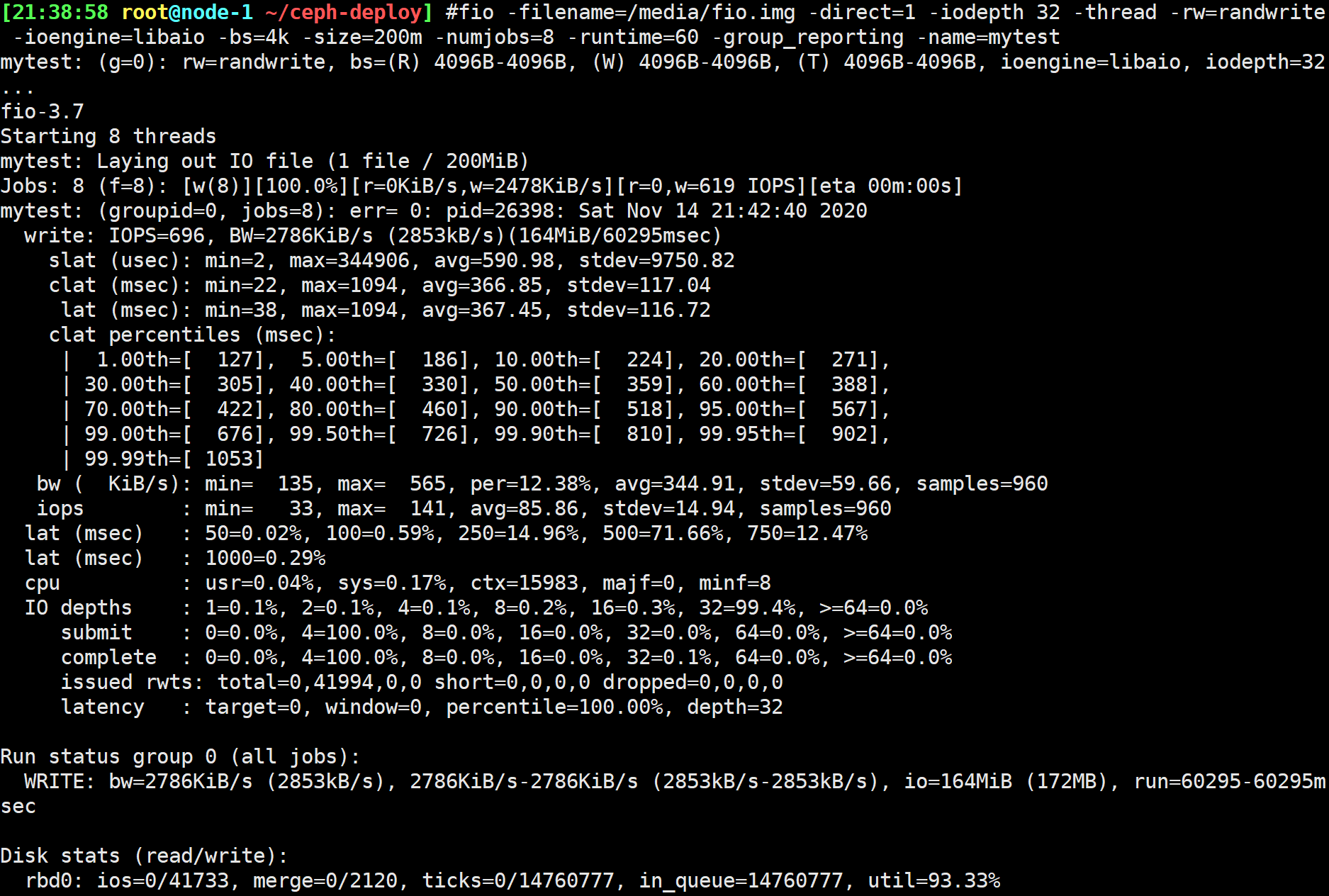
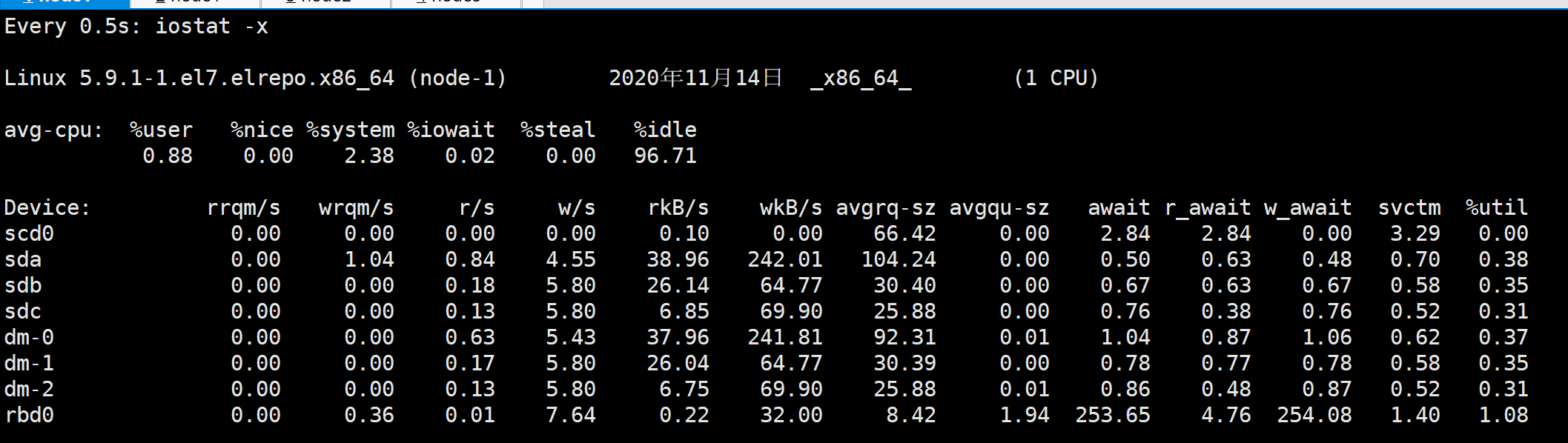
4K随机写-IOPS
1 | $ fio -filename=/media/fio.img<文件名> -direct=1 \ |
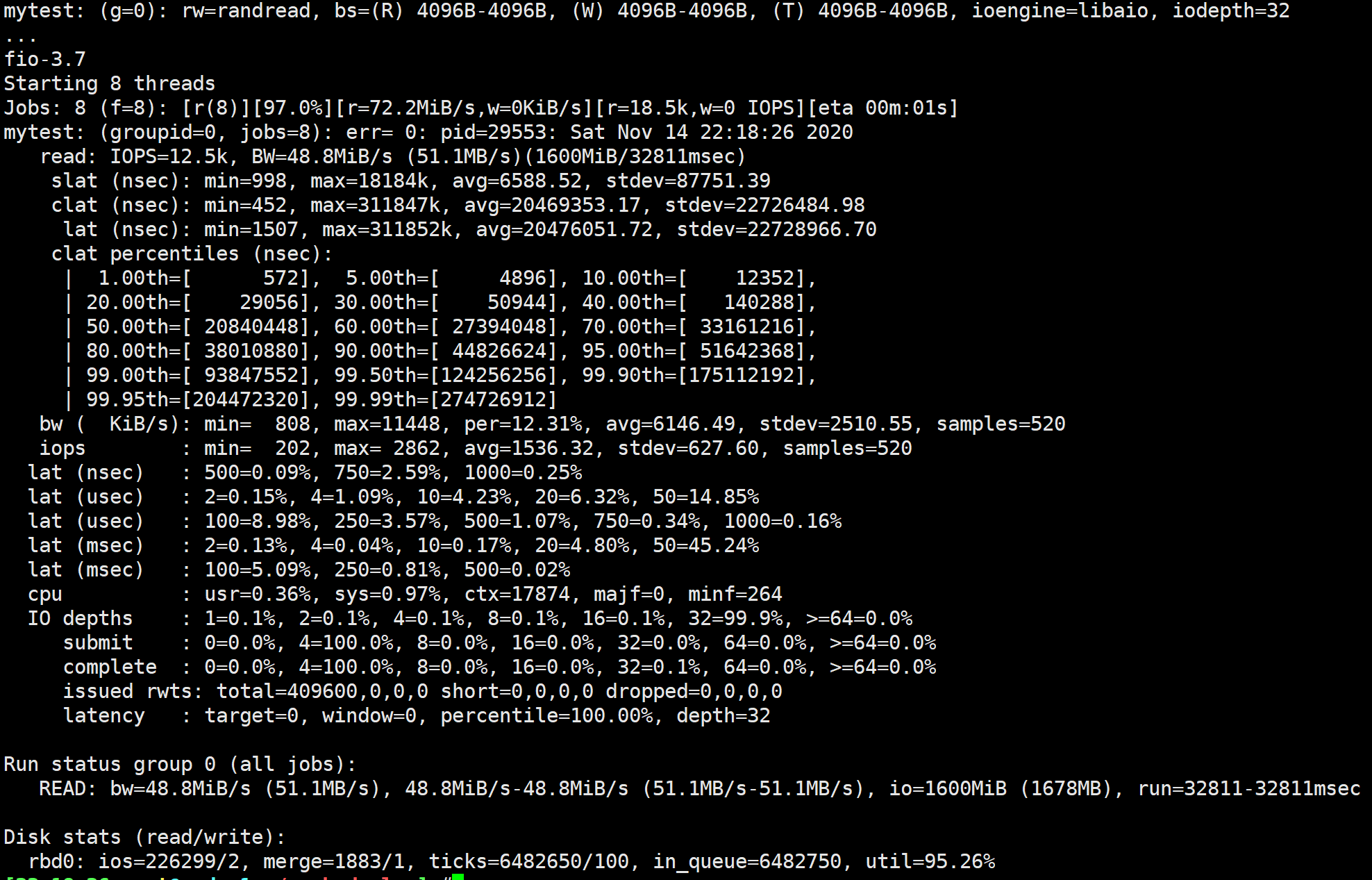
4K随机读-IOPS
1 | $ fio -filename=/media/fio.img -direct=1 -iodepth 32 -thread -rw=randread -ioengine=libaio -bs=4k -size=200m -numjobs=8 -runtime=60 -group_reporting -name=mytest |
4K随机读写-IOPS r70% w30%
1 | $ fio -filename=/media/fio.img -direct=1 -iodepth 32 -thread -rw=randrw -rwmixread=70 -ioengine=libaio -bs=4k -size=200m -numjobs=8 -runtime=60 -group_reporting -name=mytest |
1M顺序写-吞吐
1 | $ fio -filename=/media/fio.img -direct=1 -iodepth 32 -thread -rw=write -ioengine=libaio -bs=1m -size=200m -numjobs=8 -runtime=60 -group_reporting -name=mytest |
RBD Bench压力测试
1 | $ rbd help bench |
CEPH与K8s集成
官方文档https://v1-18.docs.kubernetes.io/docs/concepts/storage/volumes/
Ceph与volumes集成
1 | # 下载并安装sealos, sealos是个golang的二进制工具,直接下载拷贝到bin目录即可, release页面也可下载 |
准备工作
1、创建pool和用户
1 | [root@node-1 ~]# ceph osd pool create kubernetes 8 8 |
2、创建认证用户
1 | [root@node-1 ~]# ceph auth get-or-create client.kubernetes mon 'profile rbd' osd 'profile rbd pool=kubernetes' |
3、创建secrets对象存储将Ceph的认证key存储在Secrets中
获取步骤2生成的key,并将其加密为base64格式
1 | [root@node-1 ~]# echo AQD/6LBfg19MIhAA4UGpvND9amAsVjJtsDfvtQ== | base64 |
创建定义secrets对象
1 | apiVersion: v1 |
生成secrets
1 | [root@node-1 volumes]# kubectl apply -f secret.yaml |
容器中调用RBD volumes
1、创建rbd块
1 | [root@node-1 ~]# rbd create -p kubernetes --image-feature layering rbd.img --size 10G |
2、pod中引用RBD volumes
1 | [root@node-1 volumes]# cat pods.yaml |
测试验证
1、生成pod
1 | [root@node-1 volumes]# kubectl apply -f pods.yaml |
2、查看挂载的情况,可以看到RBD块存储挂载至data目录
1 | [root@node-1 volumes]# kubectl exec -it volume-rbd-demo -- df -h |
Ceph与PV/PVC集成
准备工作
参考步骤一,创建好pool,镜像,用户认证,secrets
定义PV和PVC
1、PV定义,定义一块存储,抽象化为PV
1 | $ rbd create -p kubernetes --image-feature layering demo-1.img --size 10G |
2、PVC定义,引用PV
1 | [root@node-1 pv_and_pvc]# cat pvc.yaml |
3、生成PV和PVC
1 | [root@node-1 pv_and_pvc]# kubectl apply -f pv.yaml |
Pod中引用PVC
1 | [root@node-1 pv_and_pvc]# cat pod-demo.yaml |
文档:
- https://blog.51cto.com/happylab/2488904
- https://github.com/kubernetes/examples/tree/master/volumes/rbd
- https://horus-k.github.io/2020/09/17/kubeasz%E5%BF%AB%E9%80%9F%E9%83%A8%E7%BD%B2%E4%BA%8C%E8%BF%9B%E5%88%B6k8s%E9%9B%86%E7%BE%A4/
Ceph与StorageClass集成
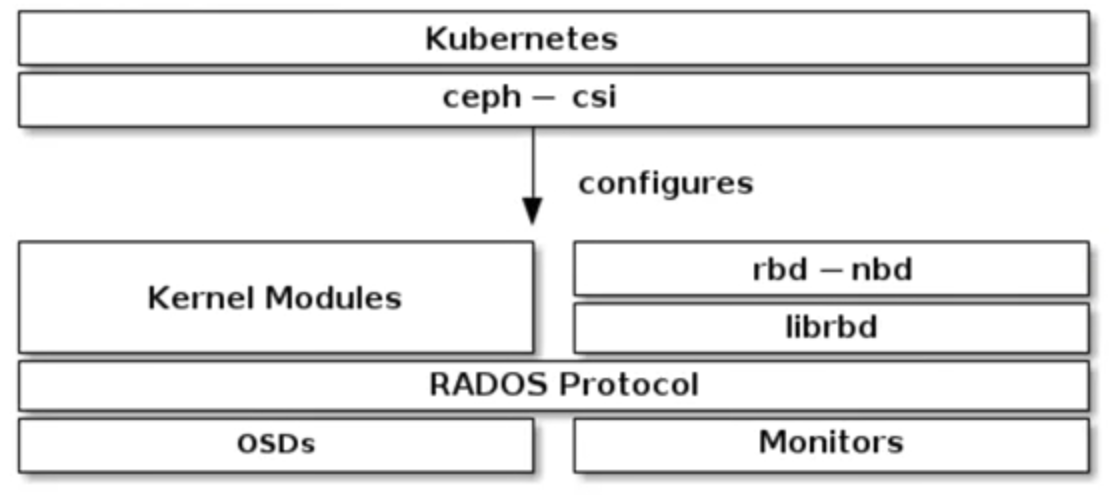
初始化
创建所需的ServiceAccount和RBAC ClusterRole / ClusterRoleBinding Kubernetes对象。这些对象不一定需要针对您的Kubernetes环境进行自定义,因此可以从 ceph -csi部署YAML中按原样使用:
1 | wget https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-provisioner-rbac.yaml |
1 |
|
1 |
|
创建sc
1 | 官网少个configmap报错 |
1 | cat <<EOF > csi-rbd-sc.yaml |
创建pvc
1 | cat <<EOF > raw-block-pvc.yaml |
创建pvc后申请pv出错,权限不足
修改为admin权限后重新创建
1 | ceph auth list |

容器调用StorageClass
1 |
|
- 如果没有升级内核会报错
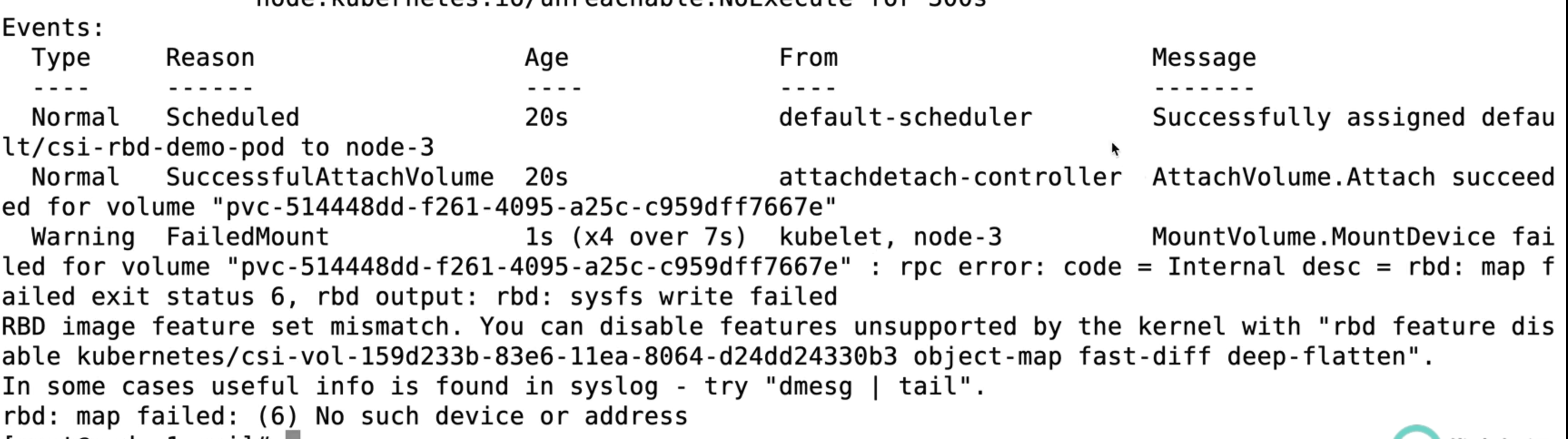
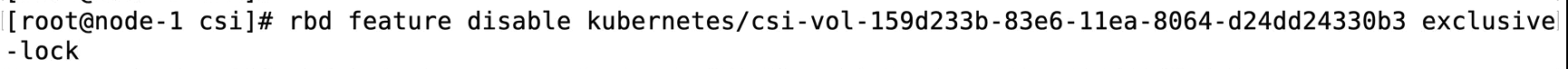
可根据提示关闭rbd特性
或者修改ceph配置
1
2
3
4
5$ ceph --admin-daemon /var/run/ceph/ceph-mon.node-1.asok config show | grep features
"enable_experimental_unrecoverable_data_corrupting_features": "",
"mon_debug_no_initial_persistent_features": "false",
"rbd_default_features": "61",
将rbd_default_features改为1 ##好像没用,要在sc里修改,生效需删除重建

Ceph与KVM集成
CEPH与OpenStack集成
环境准备
1 | 我们安装的是all-in-one环境的openstack,测试机IP:192.168.1.10 |
centos7.8回退leatherman版本
1 | yum downgrade leatherman |
2、安装pakcstack
1 | [root@openstack ~]# yum install -y openstack-packstack python-pip centos-release-openstack-train |
Ceph管理与监控
Dashboard安装
1 | $ yum install ceph-mgr-dashboard |
SSL / TLS支持
1 | ceph dashboard create-self-signed-cert |
仪表板绑定到TCP / IP地址和TCP端口。
1 | ceph config set mgr mgr/dashboard/server_addr 10.211.55.201 |